Турецкий алфавит сейчас - расширенная латиница. Большинство букв имеют по отдельности простое чтение, к какому мы привыкли в школе не на английском, где А читается примерно как Эй в одних случаях и как Э в других, а на математике и физике, где латинское А примерно соответствует нашему А. A = A, В = Б, G = Г и т.д.
Какие особенности?
Несколько букв имеют пары, в каждой из которых одна буква "без излишеств", а другая с отличительным хвостиком внизу (французский седиль в форме примерно цифры 5 без верхней полочки) у согласных или точка либо чаще двоеточие над гласной.
Эти пары есть для звуков 1) звонкого [дж] буква С без седиля и глухого [ч] та же буква с седилем Çç; 2) буква S даёт звук [с] как в Истанбул (Стамбул), а она же с седилем звук мягкого [ш'], но не лолгого в отличие от русского Щ.
Гласные [ы] и [и] обозначаются парой букв i с точкой для [и], а без точки для [ы], причём точки есть или нет и над строчной, и над прописной версиями букв. Две точки, как над нашим ё, у них отличают звуки для О [о] и Ё без [й] (буква Ö, как и в немецком), как при произнесении русского слова пёс [п'öc] ([pös]), а также U для [у] как в петух и Ü для Ю без Й, как в пюпитр [п'упитр, püpitr]. К букве Gg есть пара с галочкой сверху для продления предыдущего гласного звука или лёгкого фрикативного звука. И над буквой Аа может ставиться перевёрнутая галочка - крышечка â для обозначения Я без [й], как в слове пятница, как финское ä в Вяртсиля. Буквы W, X практически не используются. Нашему [в] соответствует буква V. Звук [й] обозначает буква Yy, а буква Jj дает всегда мягкое [ж'].
Речь идёт о звуках или о буквах?
В лингвистике термина "гласные второго ряда" нет ни для звуков, ни для букв.
Есть понятие "йотированные буквы" (е, ё, ю, я), а для звуков - гласные переднего - [и], [э], среднего -[ы], [а] и заднего ряда - [у],[о]. Под термином "ряд" в этом случае понимается горизонтальные движения языка в процессе речи.
А вот у логопедов свой взгляд на звуки-буквы, неверный с точки зрения фонетики, но приносящий практическую пользу.
Понять можно: цель - научить не анализировать звуки, а произносить их.
Именно поэтому логопеды используют понятие "гласные второго ряда" для обозначения йотированных букв.
Гласными звуками их назвать нельзя, т.к. они состоят из двух разных звуков: согласный [й*] и один из гласных [й+а]= я, [йо]= ё, [йэ]= е, [йу]= ю. Сюда же причисляют и нейотированный звук [и] по принципу обозначения мягкости согласных.
Например, в моем языке. Мой язык - якутский (саха тыла). У нас есть такие буквы Үү, Өө, ҕ, һ, и дифтонги ыа, уо, иэ, үө, а также Дь, дь, Нь, нь. Все это есть в якутском алфавите.
Например, Нөрүөн нөргүй - здравствуйте, Баһыыба - спасибо, Дьол - счастье, Уот - свет, Баҕа санаа - желание
Согласен, что в некоторых шрифтах не разобрать что чем является. Но если очень уж важно знать точно, какая буква написана, можно поступить следующим образом.
Выделите мышью непонятый фрагмент текста и скопируйте в буфер обмена.
Затем откройте какой-нибудь текстовый редактор (например программу "Блокнот") и скопируйте туда этот текст из буфера обмена.
В той программе текст будет выглядеть несколько иначе, и возможно станет понятно, какая буква где написана. Если же будет ещё не понятно, в том же текстовом редакторе измените шрифт, и посмотрите этот же текст, но написанный разными шрифтами. Рано или поздно попадётся такой шрифт, при котором английские "л" и "и" будут выглядеть по-разному. Также можно смотреть текст в одном и том же шрифте, но в разном размере шрифта, а также при выделении текста (жирный текст и курсив).
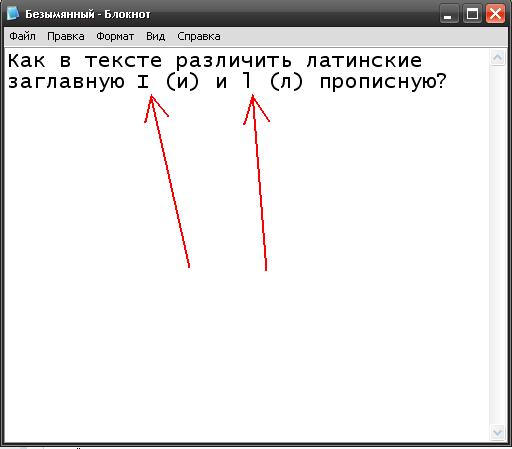
Вот, к примеру, ваш вопрос, в котором тоже непонятно где "л", а где "и", но если посмотреть на него в Блокноте шрифтом Lucida Console с размером шрифта 16, то становится понятно где и что:
Насколько мне известно, в Гавайском языке, адаптированном к английскому, насчитывается только 12 букв. Самый длинный алфавит в адаптации к английскому, Сенегальский, который включает более пятидесяти букв.