Речь идёт о звуках или о буквах?
В лингвистике термина "гласные второго ряда" нет ни для звуков, ни для букв.
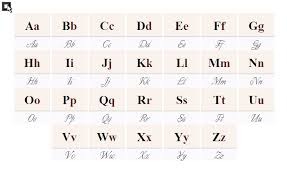
Есть понятие "йотированные буквы" (е, ё, ю, я), а для звуков - гласные переднего - [и], [э], среднего -[ы], [а] и заднего ряда - [у],[о]. Под термином "ряд" в этом случае понимается горизонтальные движения языка в процессе речи.
А вот у логопедов свой взгляд на звуки-буквы, неверный с точки зрения фонетики, но приносящий практическую пользу.
Понять можно: цель - научить не анализировать звуки, а произносить их.
Именно поэтому логопеды используют понятие "гласные второго ряда" для обозначения йотированных букв.
Гласными звуками их назвать нельзя, т.к. они состоят из двух разных звуков: согласный [й*] и один из гласных [й+а]= я, [йо]= ё, [йэ]= е, [йу]= ю. Сюда же причисляют и нейотированный звук [и] по принципу обозначения мягкости согласных.
Например, в моем языке. Мой язык - якутский (саха тыла). У нас есть такие буквы Үү, Өө, ҕ, һ, и дифтонги ыа, уо, иэ, үө, а также Дь, дь, Нь, нь. Все это есть в якутском алфавите.
Например, Нөрүөн нөргүй - здравствуйте, Баһыыба - спасибо, Дьол - счастье, Уот - свет, Баҕа санаа - желание
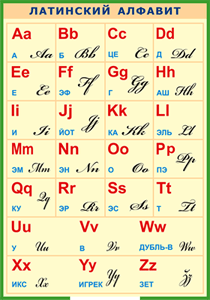
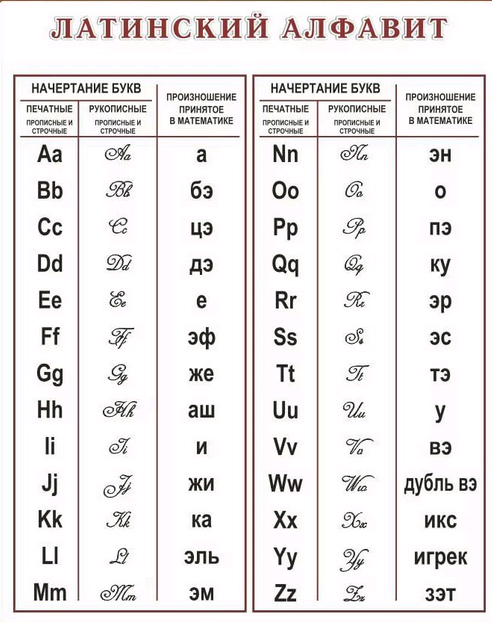
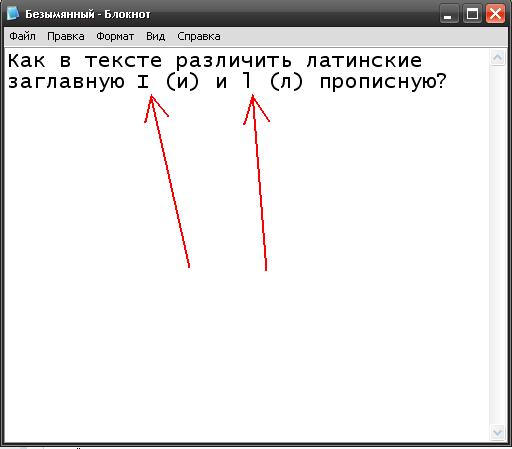
Согласен, что в некоторых шрифтах не разобрать что чем является. Но если очень уж важно знать точно, какая буква написана, можно поступить следующим образом.
Выделите мышью непонятый фрагмент текста и скопируйте в буфер обмена.
Затем откройте какой-нибудь текстовый редактор (например программу "Блокнот") и скопируйте туда этот текст из буфера обмена.
В той программе текст будет выглядеть несколько иначе, и возможно станет понятно, какая буква где написана. Если же будет ещё не понятно, в том же текстовом редакторе измените шрифт, и посмотрите этот же текст, но написанный разными шрифтами. Рано или поздно попадётся такой шрифт, при котором английские "л" и "и" будут выглядеть по-разному. Также можно смотреть текст в одном и том же шрифте, но в разном размере шрифта, а также при выделении текста (жирный текст и курсив).
Вот, к примеру, ваш вопрос, в котором тоже непонятно где "л", а где "и", но если посмотреть на него в Блокноте шрифтом Lucida Console с размером шрифта 16, то становится понятно где и что:
Буква "у" несет огромную смысловую нагрузку. Без нее сложно передать сильное удивление. Например "у-у-у-у-у, блин!" без буквы "у" сводится к нейтральному восклицанию без признаков эмоций.
С буквой "и" все гораздо сложнее, в выражениях она спокойно заменяется запятой, из многих слов ее можно удалить не теряя семантики. Наверное ее еще не успели забыть, и по привычке используют. А в алфавите ее оставили для того что бы занять пустующее место.
Или я не про то?
Есть такая панграмма, то есть алфавитное предложение, в котором содержатся практически все буквы русского алфавита:
"Съешь еще этих мягких французских булок, да выпей же чаю".
Такие панграммы используются для демонстрации шрифтов в стандартных средствах Microsoft Windows, они позволяют видеть, каким образом выглядят все буквы алфавита в кириллических шрифтах целиком, а также запятую и точку.
Можно было бы, конечно, просто пропечатать весь алфавит от начала и до конца, но это было бы очень скучно.