Как известно, первый русский алфавит, глаголица, был создан на основе греческого, цифровые значения букв тоже были подобны греческим образцам, эти же традиции перекочевали и в "кириллицу".
В ней были и свои, "русские" буквы, передающие звуки русской речи, - "б" и "ж" (в греческом их нет), однако цифровые символы всё-таки были переняты от греков. Именно поэтому "б" и "ж" не имеют значения цифр и не учитываются при подсчёте.
Буква "Н" (от греческой "h"), "иже", прообраз русской "и", занимала 8-е место, поэтому её и назвали "восьмеричной".
Буква "i" находилась на 10-м месте, поэтому получила название "и десятеричное".
На 9-м месте, между "и"/"н" и "i" некогда стояла буква "фита", но она была перенесена почти в самый конец азбуки, а цифровое значение "9" сохранила. Вот такие "путешествия" букв в русской азбуке.
Речь идёт о звуках или о буквах?
В лингвистике термина "гласные второго ряда" нет ни для звуков, ни для букв.
Есть понятие "йотированные буквы" (е, ё, ю, я), а для звуков - гласные переднего - [и], [э], среднего -[ы], [а] и заднего ряда - [у],[о]. Под термином "ряд" в этом случае понимается горизонтальные движения языка в процессе речи.
А вот у логопедов свой взгляд на звуки-буквы, неверный с точки зрения фонетики, но приносящий практическую пользу.
Понять можно: цель - научить не анализировать звуки, а произносить их.
Именно поэтому логопеды используют понятие "гласные второго ряда" для обозначения йотированных букв.
Гласными звуками их назвать нельзя, т.к. они состоят из двух разных звуков: согласный [й*] и один из гласных [й+а]= я, [йо]= ё, [йэ]= е, [йу]= ю. Сюда же причисляют и нейотированный звук [и] по принципу обозначения мягкости согласных.
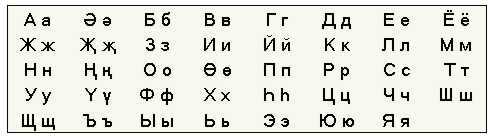
Из всего многообразия национальных алфавитов на основе кириллицы наибольшее практическое применение имеют алфавиты тюркских языков, прежде всего татарского. На нем и остановимся подробнее. К 33 буквам русского алфавита в нем добавлены еще 6 на основе кириллической и латинской графики (2-я, 10-я, 18-я, 20-я, 26-я, 29-я буквы):
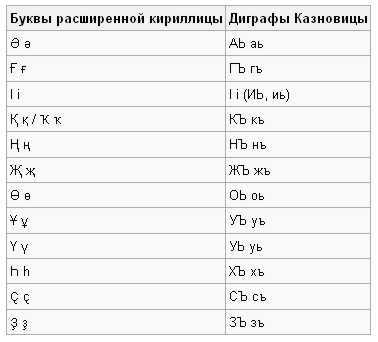
Если возникает необходимость набрать татарский текст на стандартной русской клавиатуре, то прибегают к казновице - обозначению дополнительных букв через кириллические дифтонги:
В этой таблице привелены соответствия не только для татарского, но и других значительных тюркских языков - казахского и киргизского, где есть свои дополнительные буквы.
Звонких согласных букв в русском алфавите нет, есть согласные буквы, обозначающие в определённой позиции звонкие согласные звуки.
При этом согласных звонких звуков больше, чем букв, их обозначающих.
Например, буква "б" может обозначать два разных звонких звука:[б]-(ду[б]ы) и [б*]- ([б*]елый. Во втором слове на мягкость предыдущего согласного указывает гласная буква "е". Точно такая же ситуация и с многими другими буквами, использующимися для обозначения звонких звуков.
Букв, обозначающих на письме звонкие звуки, в современном русском алфавите 11: б, в, г, д, й, ж, з, л, м, н, р.
Количество же звонких звуков, обозначаемых этими буквами, больше - 20 + долгий звук [ж], (напр., в слове "дро[ж*]и"):
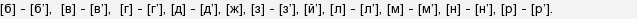
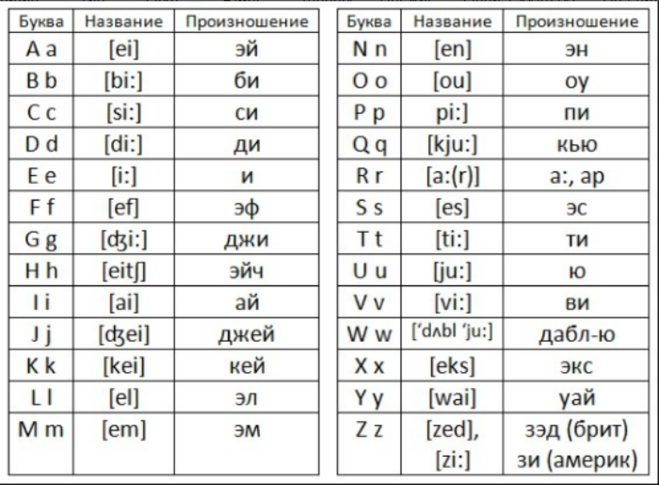
Английские буквы нужно читать не в русской транскрипции, а необходимо учиться читать значки английской транскрипции. В противном случае, человек никогда не сможет прочитать ни одного нового английского слова. В словарях (как в электронных, так и на бумажном носителе), всё-таки, даётся английская транскрипция, а не русская:-)
Тем не менее, английский алфавит с транскрипцией на английском и русском языках можно найти вот здесь.
Если же нет желания и(ли) времени для того, чтобы пройти по вышеуказанной ссылке, то можно просто-напросто скопировать вот эту картинку. На первых порах и она сойдёт при изучении английского языка.