Обычный сайт на вордпресс, наполняется с помощью парсера или граббера (кто как называет).
Формально, как для поисковиков так и для сайта "Большой Вопрос", нормы соблюдены, так как сайт не скрывает, что информация берется с определенного ресурса. Если Вы читали правила пользования сайтом "Большой вопрос", то там есть пункт 5.

Честно говоря не вижу каких либо причин для трагизма и печали.
А на тему выдачи запросов, сейчас настолько сложные алгоритмы выдачи по запросам, что даже задав один и тот же запрос, два человека могут получить совершенно разную выдачу. В алгоритмы выдачи запросов включается не только ранжирование сайтов, но еще и история поиска и посещений сайтов самого человека, его интересы и прочее. По моему толком, ну может кроме самих разработчиков, не знает как, по какому алгоритму осуществляется выдача по запросам.
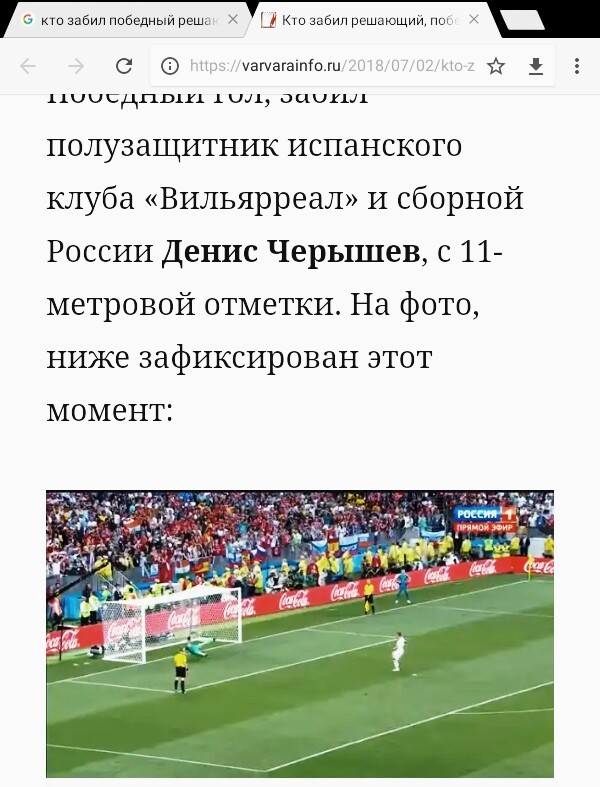
Да и вряд ли кто то будет давать вопрос именно так "Кто забил решающий, победный гол в матче Испания - Россия 1/8 финала ЧМ-18?".
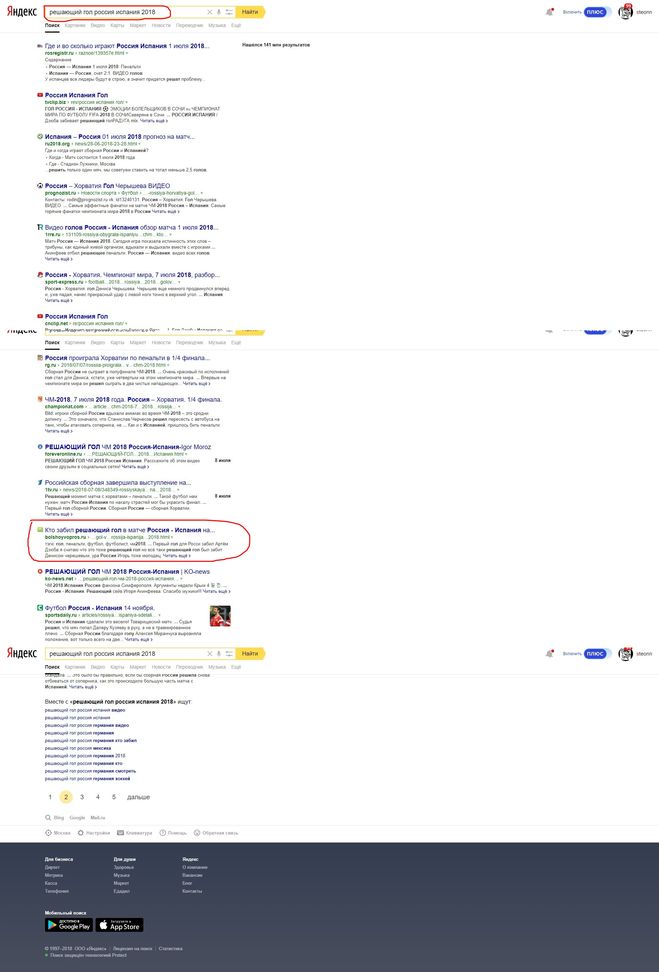
Например по запросу "решающий гол россия испания 2018" у меня выдача Вашего вопроса на второй странице, а сайта плагиатор вообще не нашел в выдачи на первых пяти страницах. Дальше просто не полез.
И если честно, совершенно не понял вопроса, "есть ли еще жертвы?". Что имеется ввиду?