Что-то мне эта каша напоминает...
Уж больно чётное количество знаков в каждом слове: 14, 28, 10, 16, 8, 12, 14, 18. И все "пары" первым байтом имеют либо "Р", либо "С". Уж больно Юникод напоминает - каждый символ в двух байтах...
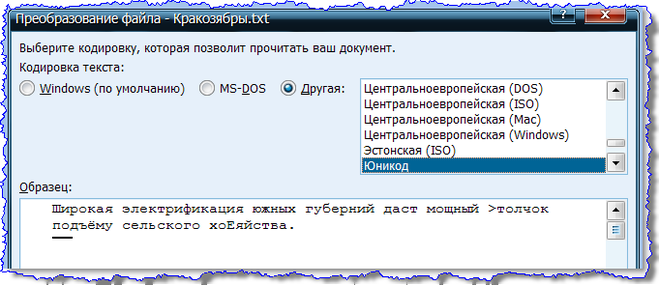
Проверяю. Копирую, вставляю в Блокноте, сохраняю
затем открываю с помощью Ворда - это позволит при загрузке выбрать кодировку:
Он, родимый!
И знак > действительно "не в тему".
Оч похоже на то, что текст отсканирован, и во время распознавания ФайнРидер (или кто-то ему подобный) заглючил - пятнышко на странице принял за знак >, вместо "з" в слове "хозяйство" выдал "Е". И сохранил это всё в кодировке Юникода (впрочем, не исключено, что это такие настройки кодировки).
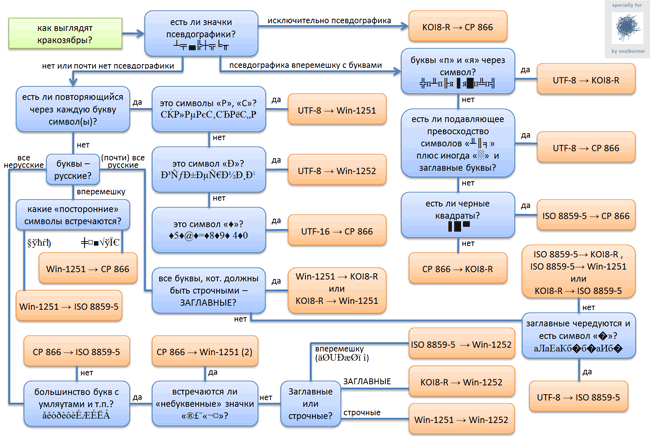
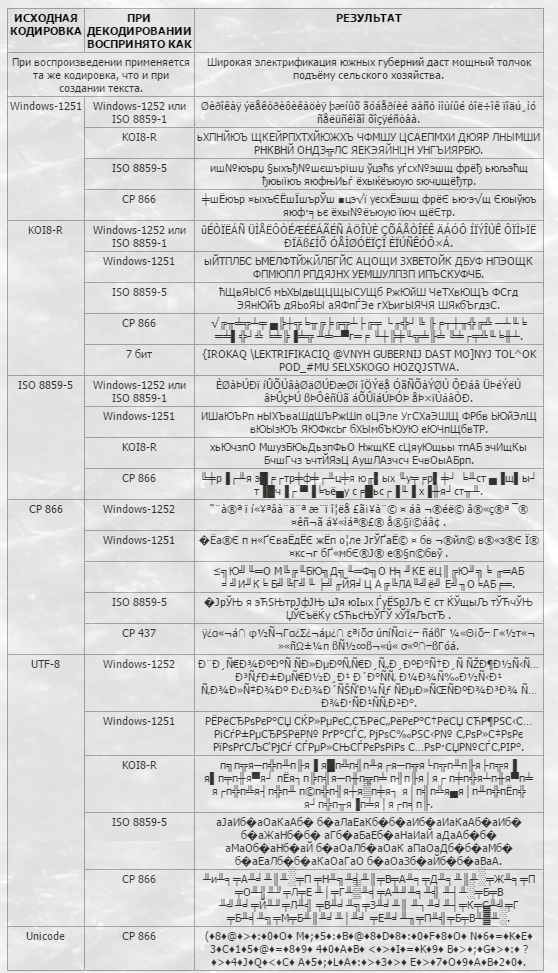
Одним словом, если нет возможности поменять кодировку (например, весь текст воспроизводится нормально, а только какой-то фрагмент кракозябрами) последовательность действий такова: копируем интересующих фрагмент в буфер, создаём новый текстовый файл, открываем его, вставляем содержимое буфера, сохраняем файл в виде текста, открываем этот файл с помощью Ворда, во время открытия - перебираем возможные варианты кодировки до получения удобочтимого результата.