в одном ответе из 100 (+-). Я чаще всего отвечаю на вопросы, ответ на которые могу дать из личного опыта. А опыт,который был получен на практике - это тоже самое, что 10 статей из Гугла, если не лучше.
В частности, я заметила уже не один раз, что не раз практически отмечаю те нюансы, которых не находила не в одной статье - такие ответы пытаюсь и здесь давать.
Поисковиком пользуюсь только если даты сверяю - не перепутала ли; или когда ищу какие-то дополнения для ответа: картинки; цитаты из словарей и тому подобное.
А отвечать о чем-то наугад я не умею. Та и зачем: здесь столько вопросов каждый день появляется и у стольких еще нет подробных ответов, что каждый сможет найти свои 10 000 вопросов, с сутью которых хорошо знаком.
В 2016 году Google представила систему нейронного машинного перевода (GNMT), которая использует искусственную нейронную сеть, для улучшения качества перевода. Нейронная модель перевода использует иные принципы работы с текстом, чем стандартный статистический метод перевода. До появления нейронных сетей перевод проводился послано - система переводила отдельные слова с учётом грамматики. Поэтому при сложных оборотах или длинных предложениях качество перевода оставлял желать лучшего. GNMT же переводит предложение целиком учитывая контекст.
Для начала, нужно оптимизировать контент таким образом, чтобы в тексте содержалось то самое, что ищут. Это предполагает, что соответствующий контент как минимум должен быть, причём крайне желательно, чтобы он был уникальный, поскольку некоторые поисковики могут учитывать дату, когда текст появился на сайте, и отбрасывать поздние. Сайты и блоги, состоящие только из перепостов чужих статей, можно даже не пытаться оптимизировать, и не тратить время и деньги на их раскрутку - всё равно поисковики будут их игнорировать и банить.
Дальше идём в заголовок страницы (HTML-страницы) как таковой или в шаблон заголовка в CMS сайта, и в тэг <keywords> через запятую перечисляем ключевые слова, по которым должен быть найден сайт. В тэг <description> пишем фразу, резюмирующую аннотацию из раздела "о сайте". Например, "Бла-бла-бла-корпорэйшн - первый интернет-магазин по продаже бла-бла-бла. Заказ онлайн, бесплатная доставка по России и СНГ." Опять же, писать следует правду. Потому что если вбить туда самые популярные запросы (порно скачать бесплатно, и иже с ними), есть вероятность, что роботы поиска зачислят ресурс в "ограниченную аудиторию", и сайт будет отображаться только в результатах именно этих запросов, в итоге его нахождаемость лишь упадёт. А если модераторы соблаговолят проверить ресурс лично, и не найдут там того, что декларируется, - точно забанят.
Это, насколько я понимаю, невозможно технически. Некоторые пользователи немного путают три понятия:
1.Сайт.
2.Поисковик.
3.Браузер.
"Большой вопрос" - это сайт. Он - не поисковик и не браузер. Он не помогает искать и не помогает находить информацию. Он её даёт. Целью БВ не является создание новой поисковой машины. На БВ есть так называемый "внутренний поиск", и он совершенно не похож на принципы работы тех поисковиков, которые выдают внешние ссылки.
Понимаете, в самом Яндексе ничего нет. Он пуст. Это не книга, не сайт. Будем считать его подобием каталога в библиотеке. Так же и Гугл. А БВ является одним из гарантий обеспечения этого каталога информационным наполнением.
Посмотреть удалённую страницу можно посмотреть в Гугле и в Яндексе. Как это сделать?
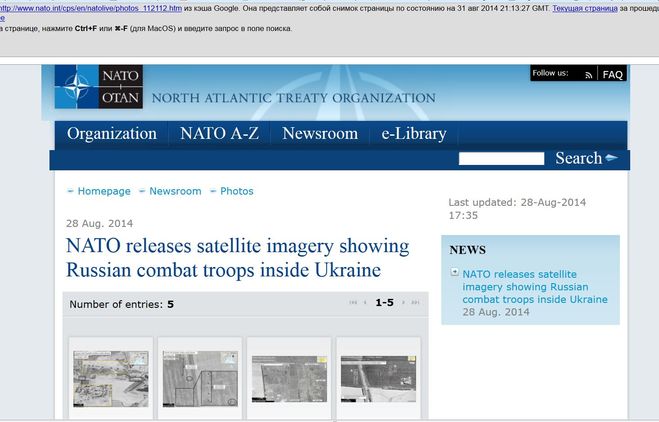
К примеру, на этой странице НАТО опубликовали якобы "спутниковые" снимки, которые должны были подтвердить, что бронетехника РФ находится на территории Украины. Когда выяснилось, что эти снимки были взяты американской разведкой из социальных сетей (позор разведке США!), они решили быстренько удалить страничку.
Теперь (02.09.2014) эта страничка выглядит вот так.
Обидно, да? Но это не страшно. Дело в том, что Гугл даёт прекрасную возможность "вытащить страничку из кэша". Любая страница сохранена в кэше поисковой системы. Достать её оттуда можно следующим образом:
- зайдите на страницу поисковой системы гугл
- в поле поиска задайте "info:". Скопируйте ссылку удалённой страницы и вставьте её после двоеточия
- теперь внизу страницы с результатами поиска Вы видите предложения "показать сохранённую в Гугле версию страницы". Кликните на это предложение и - вуаля! - перед вами удалённая страничка, её последняя сохранённая версия.
Искать удалённую страницу в кэше Яндекса можно подобным образом, только с помощью оператора "url:" и ссылки на удалённую страницу. Внизу под результатом поиска нажмите на "зелёный" адрес URL, а затем на ссылку "копия", которая появится рядом.
Вот так выглядит "спасённая" из кэша Гугла страница с фотографиями-подделками из соцсетей, предоставленных США в качестве "доказательства" присутствия войск РФ на Украине.
Учтите, что по истечении определённого времени страничка удаляется из кэша и становится полностью недоступной.