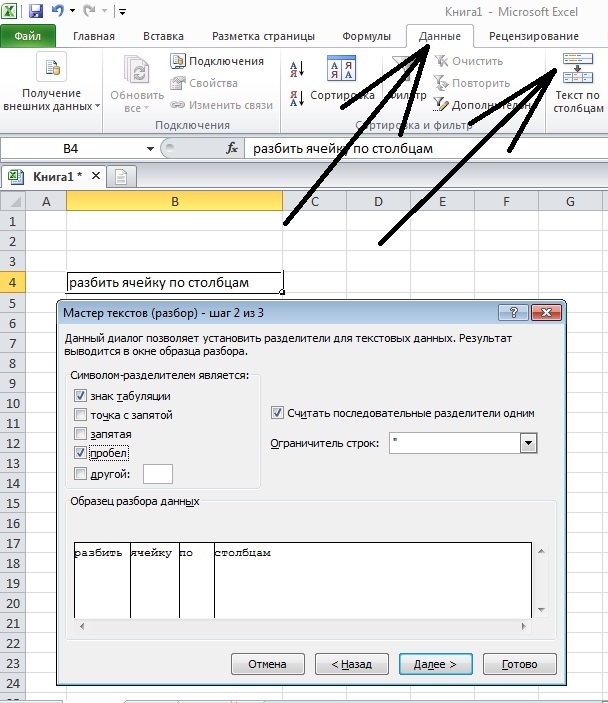
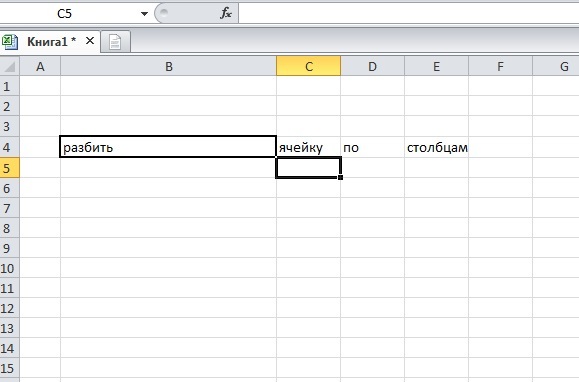
Как разбить? Хотя без разницы... Выделяете ячейку или весь столбец, далее Данные -- Текст по столбцам. В открывшемся окне выбираете тип разбиения: по разделителю (символ по которому будет произведено разбиение) или фиксированной ширины. (тогда сами мышкой ппокажете как делить). Ну и кнопками Далее - выберете формат ячеек или сразу Готово.
В экселе не надо делать таблицу, она уже сделана, потому что файл Эксель - это и есть таблица. Надо только создать новый файл и заполнить клетки данными. Для того, чтобы таблица в печатном виде выглядела таблицей, надо сделать клеткам обрамление, т.е. установить границы ячеек выбранными линиями.
Имеется ввиду к смежным ячейкам диапазона?
Написали формулу в одной ячейке и используя значок автозаполнения протянули вниз на все последующие ячейки.
Есть вариант выделить сразу весь диапазон, написать формулу и нажать сочетание клавиш Ctrl+Enter
функция СТАНДОТКЛОН определяет значения стандартного отклонения. Оно используется для определения однородности данных. Чем меньше, тем данные более однородны. Мне стандартное отклонение больше нравиться рассчитывать для данных в статике (например, анализ ассортимента или клиентов). Если данные в динамике (за период), то лучше рассчитывать коэффициент вариации для определения однородности.
Например, есть ряд данных 12 14 8 10 11. Для начала нужно рассчитать среднее значение: (12+14+8+10+11)/5=11. Далее рассчитываем Дисперсию = ((12-11)^2+(14-11)^2+(8-11)^2+(10-11)^2+(11-11)^2)/5=4. Стандартное отклонение - это корень из дисперсии, т.е. в нашем случае корень из 4 = 2.
В Excel есть СТАНДОТКЛОН.Г - стандартное отклонение для генеральной совокупности (весь диапазон данных). Тогда в формуле дисперсии числитель делим на количество данных. В нашем случае = 5.
Есть и СТАНДОТКЛОН.В -стандартное отклонение для выборочной совокупности (например, результаты маркетинговых исследований, часть клиентов и т.п.). Тогда в формуле дисперсии числитель делим на количество данных - 1. В нашем случае = 5-1=4.
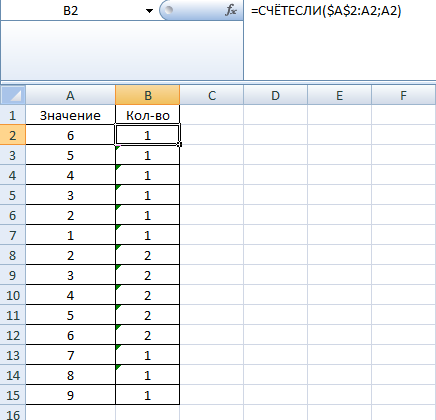
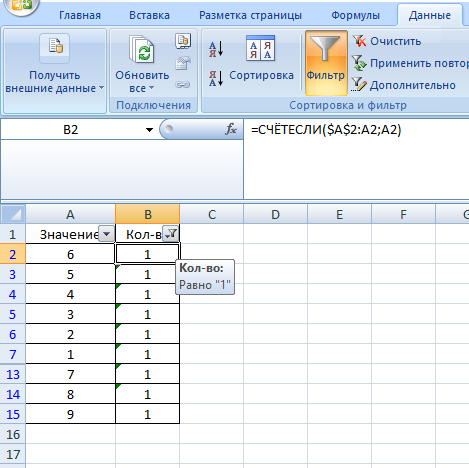
Если список значений содержится в колонке A начиная с ячейки A2 , то надо ввести дополнительную колонку, в которую для каждого значения записывать количество ячеек, содержащих данное значение в диапазоне от начала списка до текущего значения по формуле =СЧЁТЕСЛИ( $A$2:A2 ; A2 ) для первого значения, далее формула растягивается на все строки таблицы.
Все дубли будут иметь в дополнительной колонке значение больше 1.
Фильтр "=1" на дополнительную колонку скроет все дубли (Данные\Фильтр)